Fine-Tuning AI with Riku's Dataset Studio
The dataset studio in Riku makes fine-tuning models from AI21 and OpenAI simple without any code requirements. You can create your own JSONL files and then do the fine-tuning directly within Riku. Fine-tuning gives you the superpower of not being confined by the token limits of Large Language Models. For more intricate workflows or those where the task you are asking the AI to complete is more complex, fine-tuning is a path you should look at taking.
Fine-tuning is however a little bit different than prompt engineering and this blog post is all about explaining some of the common issues so you can feel confident in using the dataset studio and fine-tuning your own models. Let's get into it.
Instructions Not Required
With prompt engineering, we tend to advise that you start off your prompt with an instruction telling the AI what you want it to do. If we are building out a prompt for a blog introduction, we may write something like; 'Write a blog introduction on the following topic ensuring that it is exciting, informative and detailed catering to an audience of professionals in the electronic consumer space'. After the instruction, it would make sense to go into your input fields and then provide the example outputs.
When you use fine-tuning, you do not need to include these instructions. You can simply go into the inputs and example outputs. Staying on the same page as a blog introduction model, we could write something like this;
Blog Title: Why is Protein Important for Building Muscle
###
Proteins is an important part of a healthy diet. It provides the body with energy, it rebuilds muscles after weight lifting, helps maintain muscle mass, and it provides the body with additional nutrients. To gain the best benefits from protein, you should consume foods that contain high levels of protein. In this blog post, we'll go over the science of why it is important and give you other nutritional information for your fitness journey.
###
This is an example of how you would build this out in the playground but for the Dataset Studio, it would look a little different. There is the Prompt and the Completion and this leads nicely into our second point.
Think About Structure
Structuring your fine-tuning is important. Keeping the same structure across all of the data you provide is going to get you better outputs. If we use the above blog intro example again, we need to think about what goes into the prompt here, and what goes into the completion. If we just put the Prompt as "Blog Title: Why is Protein Important for Building Muscle" and then the completion as "<The intro paragraph". We are going to have a problem. The AI needs to know where the spacing is and without it, it might error when the fine-tune is being created.
You can do this by putting a linebreak or two between the prompt and the completion or you can use the stop sequences we recommend (###). How would this look in the Dataset Studio?
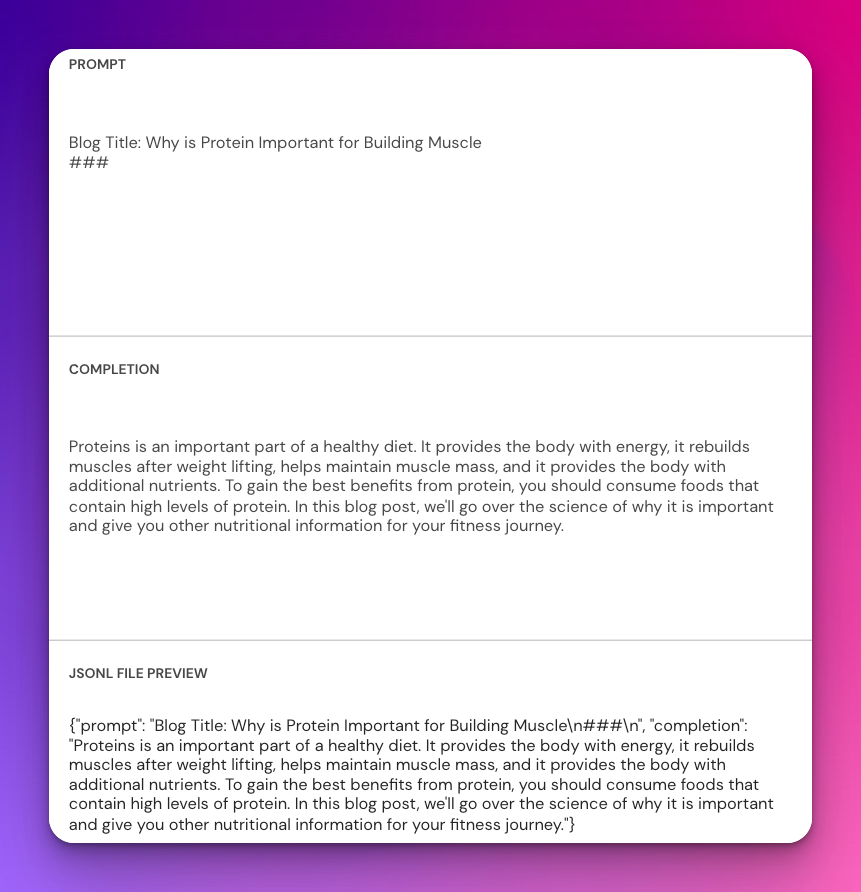
The JSONL preview shows you all the information you need to see about this. Providing a prompt in this format, and a completion like this will set you up for success. We have now got the first line in our JSONL file, happy days! Of course, the advantage of fine-tuning is that we are not confined by the token limits of building out prompts so you should take advantage of that in providing many more examples when building out a dataset.
How Many Examples Are Enough?
This is something that often comes up and the answer is really, as many as you can provide. The AI and the fine-tune will get better with more data to work with. Generally, we'd not recommend doing a fine-tune with less than 50 examples. Set 50 as the minimum level but aim for 200+. It can be difficult to get this number of examples together for your fine-tune but it will create so much better results. It is worth putting in the effort if you are serious about having AI work the best for you.
AI21 simply won't let you fine-tune with less than 50 examples so this is why we say you should provide 50 as the minimum. Remember that each prompt and completion must fit into the token limits of that model. If I am fine-tuning Curie from OpenAI, I know that Curie has a token limit of 2048 and which is approximately 8,200 characters. This means that each of my prompt and completion pairings from the Dataset Studio should not be more than 8,200 characters. If they are, the training will fail and you will get an error.
Davinci from OpenAI has a token limit of 4,000 so this means that it can handle approximately 16,000 characters per prompt and completion pairing. Going over that will result in an error. If you are planning on fine-tuning a model that isn't Davinci and think you are close to the token limits, I would suggest using AI21 as their counting of tokens seems to be more liberal than OpenAI.
How Long Does a Fine-tune take?
This depends based on the amount of data you are feeding it. A fine-tune of a small amount of data say 50 examples is going to complete faster than fine-tuning of 5,000 examples. Generally, unless your dataset is really massive, we would expect the fine-tuned model to be usable within an hour.
You can check whether it is ready if you are impatient by going to either AI21 or OpenAI directly and seeing if the fine-tune appears in the list of models available. It will appear there when it is complete. Alternatively, wait an hour and then try and run it in Riku.
How Do I Use a Fine-Tune?
We see users often trip up on this step and you have to think of your fine-tune as already having all of the information that you put into the dataset within it. You do not need to copy anything and you do not need to paste anything. If I am wanting to call the fine-tuned model for a blog introduction like we have shown examples of throughout this blog, I would simply copy that format.
I would go to the Riku playground and I would choose that model from the right sidebar. First by clicking Fine-Tuned Models and then finding the one that I had named for this task.
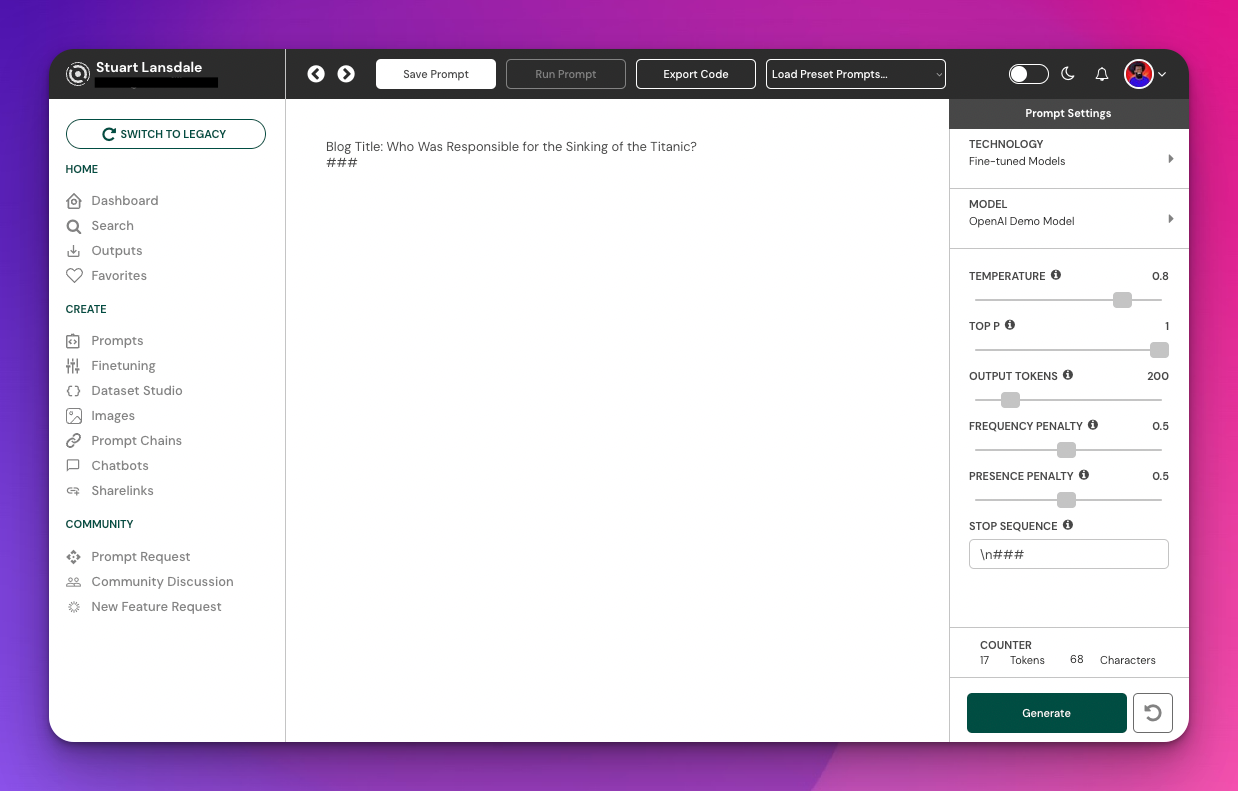
I would then remember what format I had used for my prompt and completions and replicate it here. You can see that the prompt I am using is the same as it was when I was building out the dataset, I have changed the title to be "Who Was Responsible for the Sinking of the Titanic?" and I have then put the Stop Sequence (###) and a linebreak.
At this point, everything is set up. I can toggle the temperature, top p and other settings as I desire and I can hit generate when I am ready to run the model.

Here is the output that I got. Happy with that! So I have now tested the model in the playground in Riku and if I wanted to save this so I could use it with the Single Endpoint as a saved prompt, all I would have to do is remove all of the text from the playground and hit save. Here I would choose 1 input, that input would be Blog Title: and then I would complete the save and the prompt would be ready to use.
Note that fine-tuned models are linked to specific API keys so you cannot share a fine-tuned model with other community members, unfortunately.
That is a brief introduction to fine-tuning with Riku through our dataset studio, I believe that we have covered most of the support problems and requests that we encounter from users using this for the first time. Fine-tuning really opens up a whole new world of quality and experience with AI technology and learning to grasp how to do it effectively, will make your workflows more efficient. Give us a shout if you need any further help of course!
Riku is an educational platform helping users experiment, execute and deploy all of the best large language models at scale with or without code. Our aim is to put AI into the hands of everyone and bash through the jargon so it is simple to understand and use. If you are interested in AI and don't know where to begin, our community is growing and our platform is a great place to start!